代码结构
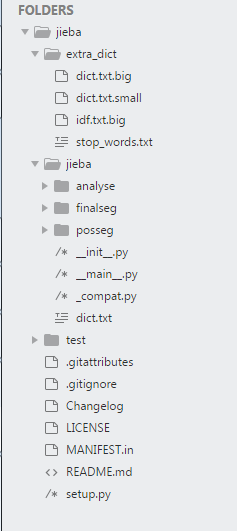
结巴分词的代码结构如下图所示。extra_dict目录下存放的是分词需要的外部数据,主要包括字典数据dict.txt、各词的idf数据idf.txt和分词前需要过滤的停用词表stop_words.txt;jieba目录是主要的程序目录,该目录下analyse为tfidf、textrank等对分词后文本抽取关键词的函数,finalseg和posseg为用HMM对文本分词的程序和数据(主要为预训练好的转移矩阵、观测矩阵和初始概率矩阵);__init__.py为jieba作为一个包来使用时的接口文件,记录了几种分词模式的;__main__是jieba直接运行时通过命令行脚本;_compat.py是用来处理python2.x和python3.x部分语法不兼容问题的。
代码流程
jieba分词分为三种模式:精确模式、全模式和搜索引擎模式,对应的调用代码如下所示(此处使用官方示例)。
|
|
输出结果如下,可以看到调用cut接口根据cut_all参数是true或false判别式全模式或者精确模式,默认为精确模式。两者的区别在于全模式输出所有在句子中可能出现的词,而精确模式只输出可能性最大的一种分词方案,并且精确模式可以用HMM预测可能为新词的词进行二次切分。搜索引擎模式则是在精确模式的基础上对长词进行再次切分以提高分词的召回率,比较适用于搜索引擎。
|
|
具体看代码,这几个部分的接口及其实现都在_init\_.py文件中的Tokenizer中完成。在包初始化时首先产生一个Tokenizer对象dt,将外部调用的载入词典、分词、生成DAG等函数赋值给相应的函数指针。
|
|
以上的几个接口都被定义为Tokenizer的成员函数,主要的有下面几个。
|
|
下面具体看分词算法的实现,对技术细节不关注的读者可以跳过这部分。
查表分词模式
如下代码所示,分词接口的代码从cut函数进入,根据参数中的HMM决定是否使用隐马尔科夫模型来进行新词预测。代码中__cut_all中返回的是yield形式的迭代式词输出,通过循环调用这些函数可以生成一个词的list。
|
|
再具体看__cut_all的代码。首先获得句子中的各个字的有向无环图,图存储为一个dict,数据结构是dict {startPos:[endPos1, endPos2…]},key值为句子中可能存在词的起始位置,value值为以该位置上的字为起始的词的所有终止位置组成的list。得到DAG后遍历dict,按照list是否大于1的两种情况将所有可能的词输出。
|
|
__cut_DAG_NO_HMM是没有使用HMM进行新词发现的精确模式,代码如下。首先和全模式类似,生成一个有向无环图;然后,调用calc(sentence, DAG, route)计算句子中各个分词组合组成句子的概率(假设句子出现的概率可以由词出现的频率相乘得到),calc生成一个dict,key为句子中的字所在的位置,value是句子末尾到这个位置组成句子的最佳分词概率(评估标准和计算方法下面介绍)和这个词的终止位置;最后对得到的dict进行逐级遍历,并将英文字符合并起来,统一输出。
|
|
cut_for_search的代码如下所示,在cut的基础上对长度大于2或大于3的词进行二次切分。
|
|
上面分词方式用到的get_DAG代码如下所示。首先,检查是否初始化(词典是否载入、模型参数是否加载),未初始化则执行初始化程序;然后用二重循环遍历句子中的词汇组合,判断该词是否能在词典中找到,若能找到则将其打包添加到DAG数据结构中。
|
|
calc的代码如下。这种算法假设句子中每个词出现的概率是相互独立的,句子出现的概率为所分词汇的乘积。基于这种假设,calc使用一种动态规划方法计算整体概率最大的分词方案和该方案得到的句子概率。这种方法动态的将分词概率计算问题分解为某个字符前后的分词概率计算问题,使用一个dict记录某个字符之后部分句子的最大概率和分词位置,然后从后面逐步向前迭代,迭代至句子开头就完成了句子整体的概率计算。
|
|
HMM分词模式
上述这些基于词典的分词方式可以解决词典中存在的词的分词问题,但是无法识别词典中不存在的词;且这种不考虑前后词关系,仅以总体出现频率判断某个词在句子出现概率的方式未免太过粗糙。针对这个问题,结巴分词采用隐马尔科夫模型(Hidden Markov Model,HMM)对序列建模。HMM分词的具体细节看这里 ,主要是把分词问题转化为一个序列状态预测问题,在状态序列中将每个单字表示为BEMS这4个状态,分别表示这个字是词的起始字、终止字、中间字和这个字是单字;在观测序列中观测到的则是这个字具体的值(hash码)。完成对状态序列的估计就完成了分词。另外,HMM是一种非监督的学习算法,给出的训练集不要预先完成分词,只需有大量语料训练即可。
在jieba分词中用HMM分词的部分接口在finalseg路径下的_init\_中。具体的cut函数代码如下,首先用strdecode函数对原文本解码,然后用中文的正则表达式匹配对解码后进行粗粒度的分解,最后对分解后的文本逐个调用内部的 __cut函数分词。
|
|
内部的__cut函数代码如下。首先调用viterbi算法输出每个字可能性最大的状态,保存在pos_list,然后根据pos_list的状态(BMES)逐段输出句子中的词。
|
|
viterbi算法实现如下,接口中的start_p、trans_p和emit_p分别为初始状态概率矩阵、状态转移概率矩阵和观测概率矩阵,矩阵中的每一项均取自然对数,用相加代替相乘;states是状态的几种可能性,即”BMES”。v为记录状态序列中每个结点在每个状态中的概率(自然对数),path为记录分别以BMES四种状态为开头的最大概率状态序列的dict,key值为BMES中的一个,value为具体的状态序列,例如BMMESBE,PrevStatus表示某个状态前面可能的状态。
初始时,将V[0][y]赋值为y状态下第一个字出现的概率,同时在path中记下第一个字的状态。此后逐步沿着句子的每一字迭代,计算每个字在不同状态下的概率,计算方式为前一字对应状态下的概率(log形式)+前一状态到当前状态的转移概率(log形式)+当前状态到当前字的观测概率(log形式),每次只计算可能的几种状态(例如B前面只可能为ES),将可能性最高的状态和概率记录下来存入V和newpath中。最终取出最后一字在ES状态下(最后一字只可能为E或S)的最大概率和状态,输出该状态下的路径。
|
|
至此,jieba分词的主要代码结构和分词模式已经比较清楚了。剩下来的问题主要有两个:1.HMM的新词发现主要依赖于训练集中的语料,如果部分词汇训练集中未出现或者出现的不多,那么新词发现是起不了作用的。此时需要将包含新词的语料加入到训练集中,对HMM重新训练;2.HMM有两个很强的假设—-当前状态只受由前一状态决定、当前输出只由当前状态决定,不能考虑上下文对当前状态的影响。目前jieba分词并没有对这个问题的解决方案,工业界较成熟的方法是最大熵HMM和条件随机场。