评估一个分类算法效果的指标主要有准确率(precision)、召回率(recall)、AUC、gini系数和F1等,在不同的应用场景下这些指标都有相应的用处。
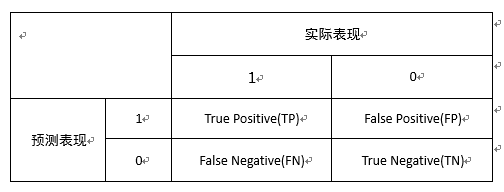
混淆矩阵
以上的指标的计算都依赖于一个混淆矩阵,如下表所示,这个混淆矩阵包括四个变量TP、FP、FN、TN,分别表示实际为正确,预测也为正确;实际为错误,预测为正确;实际为正确,预测为错误;实际为错误,预测为错误。前面的T和F表示预测的正确与否,后面的P和N表示预测目标为正确与否。
基础指标
准确率: Precision = TP/(TP+FP)
表示为分类出为正确的数据中,实际也为正确的数据占比。以商品推荐为例,这个指标表示推荐的商品最终被点击或购买的商品比例。
召回率: Recall = TP/(TP+FN)
表示为实际正确的数据中被判别为正确的数据比例。仍以商品推荐为例,这个指标表示的是被购买的商品中被算法筛选出来的商品比例。
F1: F1 = 2PR/(P+R)
F1是准确率和召回率综合起来的指标。
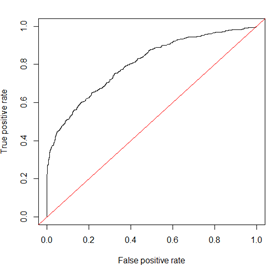
ROC曲线和相关指标
ROC曲线如下图所示,横坐标表示 FPR=FP/(FP+TN),纵坐标表示召回率TPR=TP/(TP+FN)=Recall,这两个指标分别是实际错误和正确的数据被判别为正确的数据的比例。若为一个特征设定一个阈值来判别数据的正确与否,低于阈值的数据被判别为正确,否则被判别为错误。那么随着阈值的增加,数据被判别为正确的比例会越来越高,曲线从左往右走。如果这个走的趋势为红线的趋势,即FPR和TPR完全相同,那么证明无论结果实际是正确与否,判别为正确的概率是完全相同的,即用这个特征来判别得到的结果完全是随机的,这个特征是完全无效的。如果算法有效,ROC曲线应该是高于红线的,且曲线越往左上走说明随着阈值的增加,TPR的增速越高于FPR,算法效果越好。
这样,ROC曲线包围的面积就能表示分类的效果,即AUC指标。当AUC为1时,ROC曲线完全在左上角,开始时所有正确的就都被判别为正确,错误的随着阈值增加才逐渐被判别为正确。说明这个指标的分类效果是最佳的,只需要把判别标准设定为最严格就可以把数据全部分类正确。gini系数和AUC类似,表示红线以上,黑线以下这块区域的面积。即Gini=2*AUC-1。
另外,还有一个指标KS(Kolmogorov-Smirnov)值,KS=max(TPR-FPR)也是基于ROC图表示模型性能的。这个指标描述的是当前特征最好的分类效果。这个指标相对于AUC和gini系数而言更能说明问题,在基于各分类算法中,最终一定是取最好的结果投入运行的,比较各算法分类算法效果的最佳值比均值可能更有意义。
最后,ROC曲线还可以通过光滑程度来判断模型是否过拟合。不太光滑的ROC曲线证明模型不稳定,稍微变动阈值就会模型效果较大的变化。
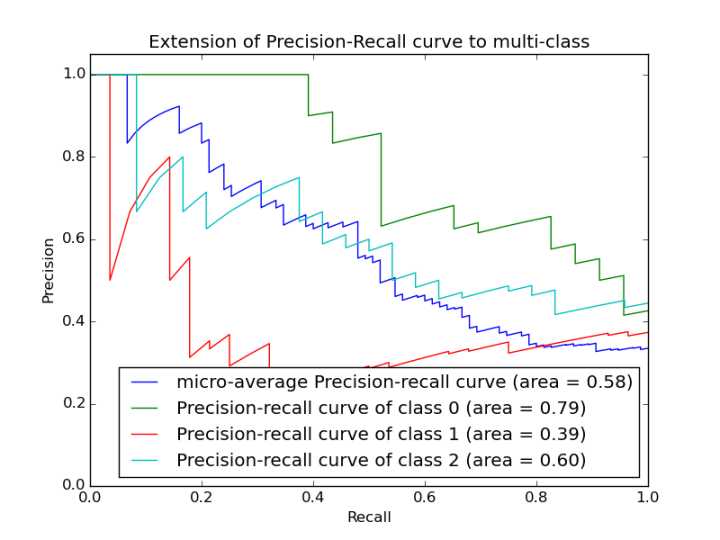
PR曲线
PR曲线(Precision-Recall curve)如下图所示,横坐标为召回率 TP/(TP+FP) ,纵坐标为准确率TP/(TP+FN)。PR曲线怎么看暂时没有弄清楚,评估曲线好坏的指标有两个曲线的高低和光滑程度。对于一条光滑的曲线来说,F1值最大的位置是在P和R都相同的位置,因此做一条y=x的直线与PR曲线相交,交点就是F1最大的位置,就F1值而言,下图中绿线最好。光滑程度的原理和ROC类似,不在赘述。
指标选择
判别指标的选择主要看具体业务对准确率或者召回率的需求。具体的说就是更偏重于检测出来数据是否正确,还是正确数据是否被检测出来。极端的例子比如地震预测,一定是更偏向于召回率,真正的地震一定要被检测出来,误报反而没那么重要。而一些风控算法或违约预测这类问题,准确率就较为重要,预测出是违约的用户确实可能违约的概率一定要大,否则冤枉别人客户体验会很差。
不是那么极端的情况一般还是以追求准确率为主,看ROC和PRC相应指标即可。